Python数据分析(三)
一、获取目录下文件列表
1、pathlib库
pathlib库的方法
创建一个Path实例(即实例化一个Path类)
from pathlib import Path
f = Path(‘E:/datafolder/dataset/test.csv')
该类的方法:
Path.cwd() #获取当前工作目录
f.exists() #判断某个实例是否存在
f.is_dir() #判断该路径是否是目录
f.is_file() #判断该路径是否是文件
f.stat().st_size #得到某个文件的大小
f.absolute() #获取绝对路径
f.parent() #获取路径的上级路径
f.name #获取文件名
f.stem #获取文件前缀
f.suffix #获取文件后缀
2、获取目录的子目录或文件
from pathlib import Path
filepath = Path('./datafolder')
for file in filepath.iterdir():
print(file)
ps.此时不获取目录中子目录下的文件
3、获取目录下所有文件
from pathlib import Path
filepath = Path(‘./datafolder')
for file in filepath.rglob('*.*'):
print(file)
ps.rglob() 函数:递归遍历所有满足条件的文件,类似于windows文件管理器用通配符进行搜索,支持前、后缀
- .: 匹配0或多个字符
- *.csv: 获取所有csv文件
- data.*: 获得名为data的所有类型的文件
二、文件批量移动
1、将所需文件放在同一目录下——筛选+复制
Step1: 设置目标路径
from pathlib import Path
import shutil
dstpath = Path('./des') #要移动到的目标文件夹目录
Step2: 筛选所需文件
filepath = Path(‘./datafolder')
filelist = filepath.rglob('*.csv')
Step3: 复制所需文件
for file in filelist:
shutil.copy(file, dstpath)
三、文件批量重命名——文件循环+文件重命名
Step1: 构想重命名的规则:
‘dataset’+ 递增数字 +’.csv’
Step2: 获取需要命名文件:
filepath = Path(‘./datafolder')
filelist = filepath.rglob('*.csv')
Step3: 依次对文件重命名:
for index, file in enumerate(filelist):
newname = 'dataset'+str(index)+'.csv'
file.rename(file.parent / newname)
四、文件批量读写
1、Pandas 实现数据连接
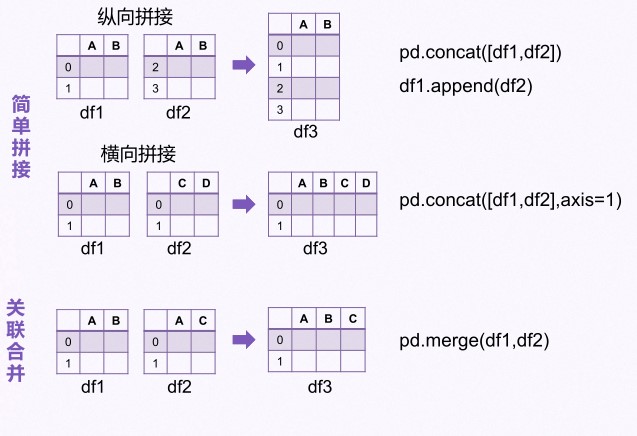
纵向拼接——把相同列不同行连接在一起
pd.concat([df1,df2])
axis = 0: 表示列对齐(默认值)
keys = [‘df1’, ‘df2’]:添加层次标识数据来源
join = ‘outer’ : 得到两个表的并集(默认值)
join = ‘inner’ : 得到两个表的交集
默认保留每个DataFrame的索引, ignore_index=False 可重排索引
——df1.append(df2)
append是concat的简略形式, 只默认在axis=0上进行合并
默认保留每个DataFrame的索引, ignore_index=False 可重排索引
横向拼接——把相同行不同列连接在一起,即行对齐,列合并
pd.concat([df1,df2],axis=1)
- axis = 1 : 表示行对齐
- keys = [‘df1’, ‘df2’]:添加层次标识数据来源
- join = ‘inner’ : 得到两个表的交集
- join = ‘outer’ : 得到两个表的并集(默认值)
- ignore_index=False 可对列索引采用默认索引
关联合并(merge)——通过一个或者多个键拼接列
pd.merge(df1, df2)
- on = ’A’: 指定合并的列名
– 如多个共存列时使用: on = [’A1’,’A2’]
– 如果合并列在两表中列名不同,则使用:left_on与right_on - how = ‘inner’ :表示合并方式
– inner(内连接,默认),outer(外连接),left(左连接),right(右连接) - suffixes = (‘df1’, ‘df2’): 标识不同数据中相同列
– 若两个DataFrame中有相同列名,可以suffixes中的元组进行标识
– 默认时加后缀_x,_y
2、文件批量读写——文件循环读取 & 内容拼接 & 数据保存
Step1: 获取需要读取的文件列表
Step2: 读取文件内容拼接在一起
Step3: 将拼接后的内容进行保存
from pathlib import Path
import pandas as pd
…
for file in filelist:
df = pd.read_csv(file)
#按需进行数据合并操作并得到mergeData
mergeData.to_csv(‘./alldata.csv‘, index = False)


