Python数据分析(二)
Pandas介绍
Pandas是一个高性能,易使用的数据结构和数据分析工具,大致可以相当于Python中的Excel。
Pandas的使用
使用前先导入:
import pandas as pd
Pandas两大数据结构
1、Series
Series是带索引的一维数组,是Pandas的主要数据结构之一,可存储整数、浮点数、字符串等类型的数据。
eg.
隐式索引(索引从0开始)
pd.Series([1,'apple',3.5,4])
自定义索引(添加index参数)
pd.Series([1,'apple',3.5,4],index = ['a','b','c','d'])
ps.索引个数需要与数据个数对应,否则会报错
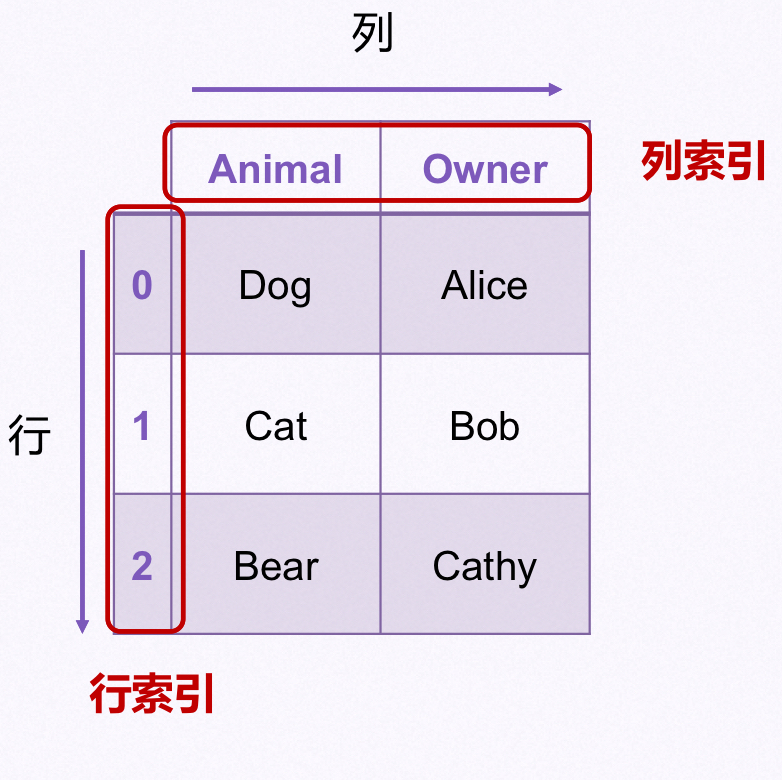
2、DataFrame
DataFrame是既有行索引,又有列索引的二维表格型数据结构,可以看成由多个series组成
pd.DataFrame({'Animal':['Dog','Cat','Bear'],'Owner':['Alice','Bob','Cathy']})
上面例子中存储了一个字典,字典的键’animal’和’owner’是每一列的表头索引,每一行的索引从0开始为0,1,2
使用Pandas读写文件
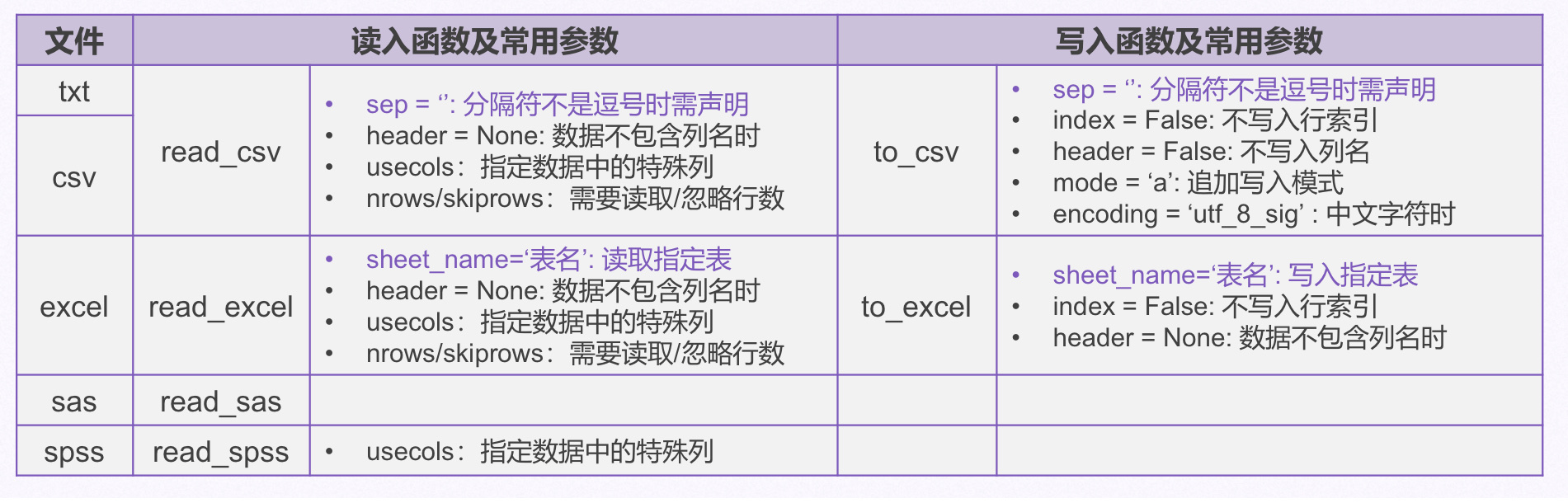
1、 全部读取txt文件和csv文件
csv文件为逗号分隔值文件
import pandas as pd
data = pd.read_csv('path',seq = '',header = None)
path为文件路径,seq参数为分隔值,读取csv时可省略,header参数在第一行不是列名时可添加。
2、部分读取txt文件和csv文件
读取指定列:
import pandas as pd
data = pd.read_csv('path',usecols = ['id','age'])
usecols = [‘1’,’3’]可以读取第二列和第四列
读取前面n行:
import pandas as pd
data = pd.read_csv('path',nrows = 2)
读取跳过包含列名在内的前两行
从第n行开始读取:
pd.read_csv('path',skiprows = 2)
从第三行开始读取
3、文件写入
覆盖式写入:
data.to_csv('path',index = False)
index = Fasle为行索引不写入,如果含中文,添加 encoding = ‘utf_8_sig’
追加式写入:
data.to_csv('path',mode = 'a',header = False)
mode = ‘a’如果存在,则追加;如果不存在,则创建
header = False 不重复写入列名
Excel文件的读写
读取:
单一Sheet文件:
data = pd.read_excel('path')
多个Sheet文件:
data = pd.read_excel('path',sheet_name = '表名')
读取指定列时使用usecols
data = pd.read_excel('path',usecols = [1,3])
写入:
单一Sheet:
data.to_excel('path',sheet_name = 'sheet1',index = False) #写入时不写入行索引
多个Sheet:
writefile = 'path'
with pd.ExcelWriter(writefile) as writer:
data.to_excel(writer,sheet_name = 'sheet1',index = False)
data1.to_excel(writer,sheet_name = 'sheet2',index = False)
数据分析文件
Pandas可以读取sas文件和spss文件,但不可以写入。